Logistic regression is a statistical method used to model the probability of a certain outcome or event occurring based on a set of input variables. It is mostly used in classification tasks. Then why is it called regression? Because It doesn’t predict a class; rather, it predicts the probability of a data point belonging to a class.
Hypothesis function
![\[\hat{y} = h_{\theta}(x) = g(\theta^{T}x)\]](https://akashnotes.com/wp-content/ql-cache/quicklatex.com-a401e8bc6f4fc4eae325b8ee413d905d_l3.png "Rendered by QuickLaTeX.com")
where:
![\[g(z) = \frac{1}{1+e^{-z}}\]](https://akashnotes.com/wp-content/ql-cache/quicklatex.com-9211427f8cad240c55cac1fbc74072f9_l3.png "Rendered by QuickLaTeX.com")
this function is called the sigmoid function or logistic function.
To better comprehend the hypothesis function of logistic regression, let’s break it down. The term θ^Tx, which is analogous to linear regression, represents the weighted sum of the input variables. However, in logistic regression, the sigmoid function is applied to this sum to transform it into a suitable form.
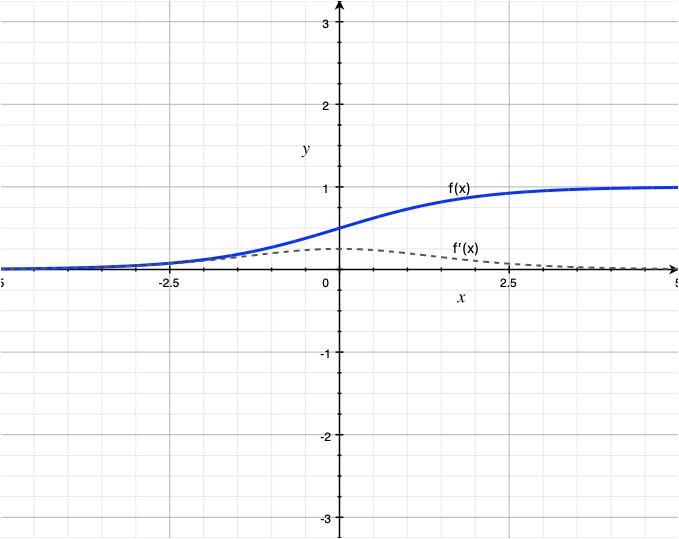
The sigmoid function plays a crucial role in logistic regression by squashing the output to a range between 0 and 1, allowing it to represent a probability.
Cost function
![\[BCE = -\frac{1}{n}\sum_{i=1}^{n}Cost(\hat{y}, y) = -\frac{1}{n}\sum_{i=1}^{n}y_{i}log(\hat{y_{i}}) + (1 - y_{i})log(1 - \hat{y_{i}})\]](https://akashnotes.com/wp-content/ql-cache/quicklatex.com-8cb5db7dff408c4abe88d676967e7233_l3.png "Rendered by QuickLaTeX.com")
The cost function in logistic regression, also known as the log loss or binary cross-entropy loss, is used to evaluate the model’s performance and determine how well it predicts the binary outcomes. The goal is to minimize the cost function to obtain the optimal set of model parameters.
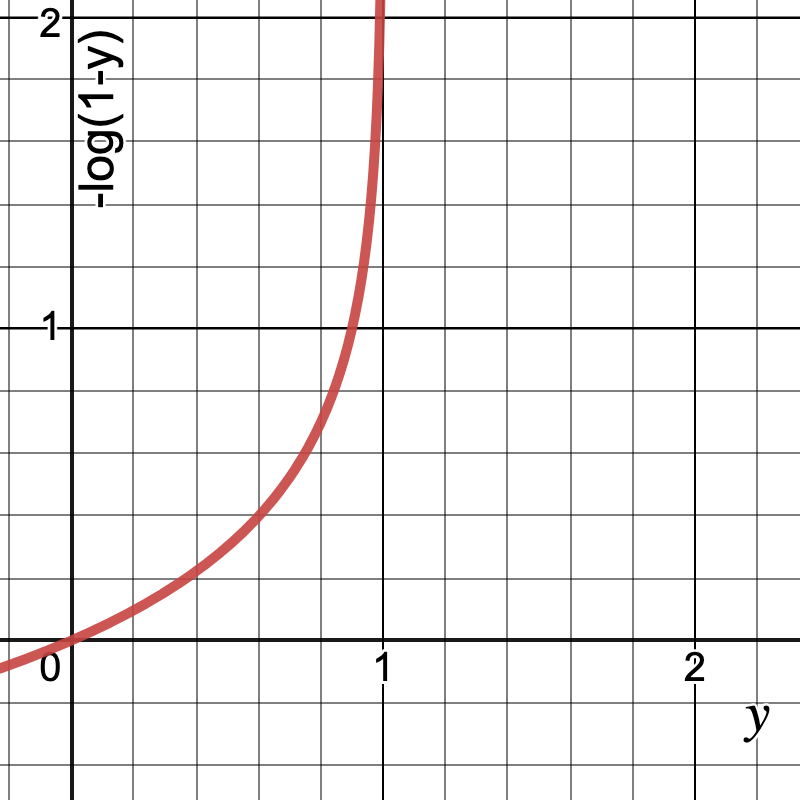
Let us break down and understand the cost function.
![\[Cost(y) =\begin{cases}-log(\hat{y_{i}})& \text{ if } y= 1\\-log(1 - \hat{y_{i}})& \text{ if } y= 0\end{cases}\]](https://akashnotes.com/wp-content/ql-cache/quicklatex.com-b550f1e27af145b99b730bdecf6b9543_l3.png "Rendered by QuickLaTeX.com")
Plotting the graph for the above equation:

Optimizers
The optimizer is the same as in linear regression i.e. we use gradient descent optimizer for most of our algorithms. To know more about optimizers you can refer to: