In the realm of machine learning and data modeling, achieving the perfect balance between a model’s ability to generalize and its tendency to memorize the training data is a critical challenge. This tutorial will dive deep into the concepts of underfitting and overfitting, two common yet contrasting pitfalls that can hinder the performance of your models. We will explore the nuances of these phenomena, understand the signs that indicate their presence, and equip you with strategies to navigate them effectively. Whether you’re a novice or an experienced practitioner, mastering the art of finding the right fit for your models is essential for building robust and accurate predictive systems.
Underfitting
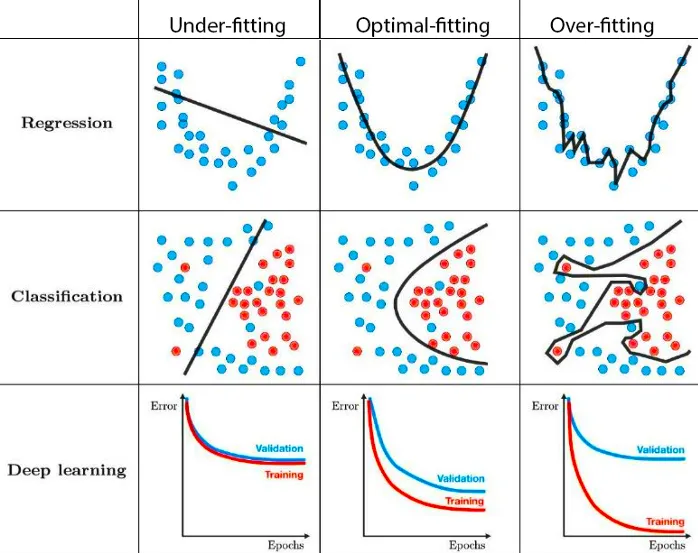
Underfitting occurs when a machine learning model is unable to capture the underlying patterns and relationships in the training data, resulting in poor performance and low predictive accuracy. An underfit model is overly simplistic and fails to generalize well to unseen data.
Underfitting commonly happens when:
- The model is too simple: If the model is not complex enough to represent the complexity of the data, it may not capture important features and relationships. For example, using a linear model to fit a non-linear relationship between the variables may lead to underfitting.
- Insufficient training: If the model is trained on a small dataset or not exposed to enough diverse examples, it may not learn the full range of patterns and variations present in the data.
- Inadequate features: If the model lacks relevant features or the input variables are not informative enough, it may struggle to make accurate predictions.
Signs of underfitting include:
- High training and testing error: The model performs poorly on both the training and testing data, indicating a lack of fit to the underlying patterns.
To address underfitting, various strategies can be employed:
- Increase model complexity: Use a more sophisticated model that can capture the complexity of the data, such as using a deeper neural network or a more flexible algorithm.
- Add more features: Include additional relevant features or create new derived features to provide the model with more information and improve its ability to capture patterns.
- Gather more data: Obtain a larger and more diverse dataset to expose the model to a broader range of examples and variations in the data.
- Adjust regularization: If regularization is applied, reducing its strength or removing it completely can help the model fit the training data more closely.
- Fine-tune hyperparameters: Experiment with different hyperparameter settings, such as learning rate or regularization parameter, to find the optimal configuration for the model.
Overfitting
Overfitting occurs when a machine learning model performs exceptionally well on the training data but fails to generalize to unseen data or new examples. The model essentially memorizes the training data instead of learning the underlying patterns, resulting in poor performance when applied to real-world scenarios.
Overfitting commonly happens when:
- Model complexity is too high: If the model is excessively complex, it can learn to represent noise or random fluctuations in the training data, leading to poor generalization to new examples.
- Insufficient training data: When the available training data is limited, the model may learn to fit the noise or specific characteristics of the training set, rather than capturing the true underlying patterns in the broader population.
Signs of overfitting include:
- Low training error but high testing error: The model performs exceedingly well on the training data, achieving a low error rate. However, when evaluated on unseen data, the performance deteriorates significantly.
- Highly complex or erratic decision boundaries: Visual representations of the model’s decision boundaries may reveal convoluted or irregular shapes that closely fit the training data but do not align with the expected patterns.
To mitigate overfitting, several strategies can be employed:
- Simplify the model: Use a less complex model architecture, reducing the number of layers, nodes, or parameters to promote simplicity and prevent the model from fitting noise.
- Increase training data: Gather more diverse and representative training data to provide the model with a broader range of examples and patterns to learn from.
- Use regularization techniques: Apply regularization methods, such as L1 or L2 regularization, to penalize complex models and encourage parameter values to be closer to zero, promoting simplicity.
- Cross-validation: Employ techniques like k-fold cross-validation to assess the model’s performance on multiple subsets of the data and identify potential overfitting.
- Feature selection: Carefully select relevant features or use dimensionality reduction techniques to focus on the most informative attributes and reduce noise in the input data.
In the next section, we are going to deep dive into one of the techniques to avoid overfitting – Regularization.